Enhancing the Settings Validator¶
Overview of Current Validation Checks¶
Below is a summary of the key validation checks currently implemented by our settings validator. For detailed information, please refer to the source code:
- Blocking Rules and Comparison Levels Validation: Ensures that the user’s blocking rules and comparison levels are correctly imported from the designated library, and that they contain the necessary details for effective use within the Splink.
- Column Existence Verification: Verifies the presence of columns specified in the user’s settings across all input dataframes, preventing errors due to missing data fields.
- Miscellaneous Checks: Conducts a range of additional checks aimed at providing clear and informative error messages, facilitating smoother user experiences when deviations from typical Splink usage are detected.
Extending Validation Logic¶
If you are introducing new validation checks that deviate from the existing ones, please incorporate them as functions within a new script located in the splink/settings_validation directory. This ensures that all validation logic is centrally managed and easily maintainable.
Error handling and logging¶
Error handling and logging in the settings validator takes the following forms:
- Raising INFO level logs - These are raised when the settings validator detects an issue with the user's settings dictionary. These logs are intended to provide the user with information on how to rectify the issue, but should not halt the program.
- Raising single exceptions - Raise a built-in Python or Splink exception in response to finding an error.
- Concurrently raising multiple exceptions - In some instances, it makes sense to raise multiple errors simultaneously, so as not to disrupt the program. This is achieved using the
ErrorLoggerclass.
The first two use standard Python logging and exception handling. The third is a custom class, covered in more detail below.
You should look to use whichever makes the most sense given your requirements.
Raising multiple exceptions concurrently¶
Raising multiple exceptions simultaneously provides users with faster and more manageable feedback, avoiding the tedious back-and-forth that typically occurs when errors are reported and addressed one at a time.
To enable the logging of multiple errors in a single check, the ErrorLogger class can be utilised. This is designed to operate similarly to a list, allowing the storing of errors using the append method.
Once all errors have been logged, you can raise them with the raise_and_log_all_errors method. This will raise an exception of your choice and report all stored errors to the user.
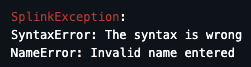
ErrorLogger in practice
from splink.exceptions import ErrorLogger
# Create an error logger instance
e = ErrorLogger()
# Log your errors
e.append(SyntaxError("The syntax is wrong"))
e.append(NameError("Invalid name entered"))
# Raise your errors
e.raise_and_log_all_errors()
Expanding miscellaneous checks¶
Miscellaneous checks should be added as standalone functions within an appropriate check inside splink/settings_validation. These functions can then be integrated into the linker's startup process for validation.
An example of a miscellaneous check is the validate_dialect function. This assesses whether the settings dialect aligns with the linker's dialect.
This is then injected into the _validate_settings method within our linker, as seen here.
Additional comparison and blocking rule checks¶
Comparison and Blocking Rule checks can be found within the valid_types.py script.
These checks currently interface with the ErrorLogger class which is used to store and raise multiple errors simultaneously (see above).
If you wish to expand the current set of tests, it is advised that you incorporate any new checks into either log_comparison_errors or _validate_settings (mentioned above).
Checking for the existence of user specified columns¶
Column and SQL validation is performed within log_invalid_columns.py.
The aim of this script is to check that the columns specified by the user exist within the input dataframe(s). If any invalid columns are found, the script will log this with the user.
Should you need to include extra checks to assess the validity of columns supplied by a user, your primary focus should be on the column_lookups.py script.
There are two main classes within this script that can be used or extended to perform additional column checks:
InvalidCols
InvalidCols is a NamedTuple, used to construct the bulk of our log strings. This accepts a list of columns and the type of error, producing a complete log string when requested.
For simplicity, there are three partial implementations to cover the most common cases:
- MissingColumnsLogGenerator - missing column identified.
- InvalidTableNamesLogGenerator - table name entered by the user is missing or invalid.
- InvalidColumnSuffixesLogGenerator - _l and _r suffixes are missing or invalid.
In practice, this can be used as follows:
# Store our invalid columns
my_invalid_cols = MissingColumnsLogGenerator(["first_col", "second_col"])
# Construct the corresponding log string
my_invalid_cols.construct_log_string()
InvalidColumnsLogger
InvalidColumnsLogger takes in a series of cleansed columns from your settings object (see SettingsColumnCleaner) and runs a series of validation checks to assess whether the column(s) are present within the underlying dataframes.
Any invalid columns are stored in an InvalidCols instance (see above), which is then used to construct a log string.
Logs are output to the user at the INFO level.
To extend the column checks, you simply need to add an additional validation method to the InvalidColumnsLogger class. Checks must be added as a new method and then called within construct_output_logs.
Single column, multi-column and SQL checks¶
Single and multi-column¶
Single and multi-column checks are relatively straightforward. Assuming you have a clean set of columns, you can leverage the check_for_missing_settings_column function.
This expects the following arguments: * settings_id: the name of the settings ID. This is only used for logging and does not necessarily need to match the true ID. * settings_column_to_check: the column(s) you wish to validate. * valid_input_dataframe_columns: the cleaned columns from your all input dataframes.
Checking columns in SQL statements¶
Checking SQL statements is a little more complex, given the need to parse SQL in order to extract your column names.
To do this, you can leverage the check_for_missing_or_invalid_columns_in_sql_strings function.
This expects the following arguments: * sql_dialect: The SQL dialect used by the linker. * sql_strings: A list of SQL strings. * valid_input_dataframe_columns: The list of columns identified in your input dataframe(s). * additional_validation_checks: Functions used to check for other issues with the parsed SQL string, namely, table name and column suffix validation.
NB: for nested SQL statements, you'll need to add an additional loop. See check_comparison_for_missing_or_invalid_sql_strings for more details.