cumulative_num_comparisons_from_blocking_rules_chart_chart¶
At a glance
Useful for: Counting the number of comparisons generated by Blocking Rules.
API Documentation: cumulative_num_comparisons_from_blocking_rules_chart()
What is needed to generate the chart? A linker with some data and a settings dictionary defining some Blocking Rules.
Worked Example¶
from splink.duckdb.linker import DuckDBLinker
import splink.duckdb.comparison_library as cl
import splink.duckdb.comparison_template_library as ctl
from splink.duckdb.blocking_rule_library import block_on
from splink.datasets import splink_datasets
import logging, sys
logging.disable(sys.maxsize)
df = splink_datasets.fake_1000
settings = {
"link_type": "dedupe_only",
"blocking_rules_to_generate_predictions": [
block_on("first_name"),
block_on("surname"),
block_on("email")
]
}
linker = DuckDBLinker(df, settings)
linker.cumulative_num_comparisons_from_blocking_rules_chart()
Alternatively, Blocking Rules can be passed into the chart directly:
brs = [
block_on(["first_name", "dob"]),
block_on("surname"),
block_on("email")
]
linker.cumulative_num_comparisons_from_blocking_rules_chart(brs)
What the chart shows¶
The cumulative_num_comparisons_from_blocking_rules_chart shows the count of pairwise comparisons generated by a set of blocking rules.
What the chart tooltip shows
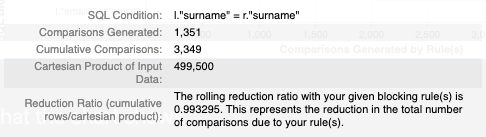
The tooltip shows a number of statistics based on the bar that the user is hovering over, including:
- The blocking rule as an SQL statement.
- The number of additional pairwise comparisons generated by the blocking rule.
- The cumulative number of pairwise comparisons generated by the blocking rule and the previous blocking rules.
- The total number of possible pariwise comparisons (i.e. the Cartesian product). This represents the number of comparisons which would need to be evaluated if no blocking was implemented.
- The percentage of possible pairwise comparisons excluded by the blocking rule and the previous blocking rules (i.e. the Reduction Ratio). This is calculated as \(1-\frac{\textsf{cumulative comparisons}}{\textsf{total possible comparisons}}\).
How to interpret the chart¶
Blocking rules are order dependent, therefore each bar in this chart shows the additional comparisons generated ontop of the previous blocking rules.
For example, the chart above shows an exact match on surname generates an additional 1351 comparisons. If we reverse the order of the surname and first_name blocking rules:
settings = {
"link_type": "dedupe_only",
"blocking_rules_to_generate_predictions": [
block_on("surname"),
block_on("first_name"),
block_on("email")
]
}
linker = DuckDBLinker(df, settings)
linker.cumulative_num_comparisons_from_blocking_rules_chart()
The total number of comparisons is the same (3,664), but now 1,638 have been generated by the surname blocking rule. This suggests that 287 record comparisons have the same first_name and surname.
Actions to take as a result of the chart¶
The main aim of this chart is to understand how many comparisons are generated by blocking rules that the Splink model will consider. The number of comparisons is the main primary driver of the amount of computational resource required for Splink model training, predictions etc. (i.e. how long things will take to run).
The number of comparisons that are appropriate for a model varies. In general, if a model is taking hours to run (unless you are working with 100+ million records), it could be helpful to reduce the number of comparisons by defining more restrictive blocking rules.
For instance, there are many people who could share the same first_name in the example above you may want to add an additonal requirement for a match on dob as well to reduce the number of records the model needs to consider.
settings = {
"link_type": "dedupe_only",
"blocking_rules_to_generate_predictions": [
block_on(["first_name", "dob"]),
block_on("surname"),
block_on("email")
]
}
linker = DuckDBLinker(df, settings)
linker.cumulative_num_comparisons_from_blocking_rules_chart()
Here, the total number of records pairs considered by the model have been reduced from 3,664 to 2,213.
Further Reading
For a deeper dive on blocking, please refer to the Blocking Topic Guides.
For more on the blocking tools in Splink, please refer to the Blocking API documentation.