
Fast, accurate and scalable probabilistic data linkage¶
Splink is a Python package for probabilistic record linkage (entity resolution) that allows you to deduplicate and link records from datasets without unique identifiers.
Key Features¶
⚡ Speed: Capable of linking a million records on a laptop in approximately one minute.
🎯 Accuracy: Full support for term frequency adjustments and user-defined fuzzy matching logic.
🌐 Scalability: Execute linkage jobs in Python (using DuckDB) or big-data backends like AWS Athena or Spark for 100+ million records.
🎓 Unsupervised Learning: No training data is required, as models can be trained using an unsupervised approach.
📊 Interactive Outputs: Provides a wide range of interactive outputs to help users understand their model and diagnose linkage problems.
Splink's core linkage algorithm is based on Fellegi-Sunter's model of record linkage, with various customizations to improve accuracy.
What does Splink do?¶
Consider the following records that lack a unique person identifier:
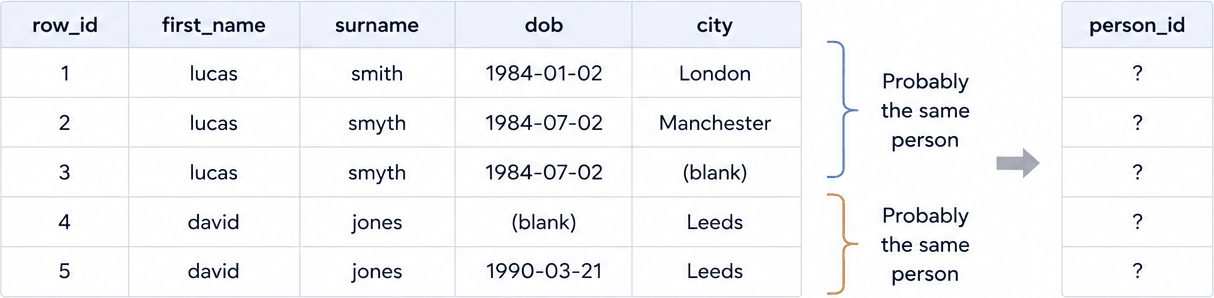
Splink predicts which rows link together:
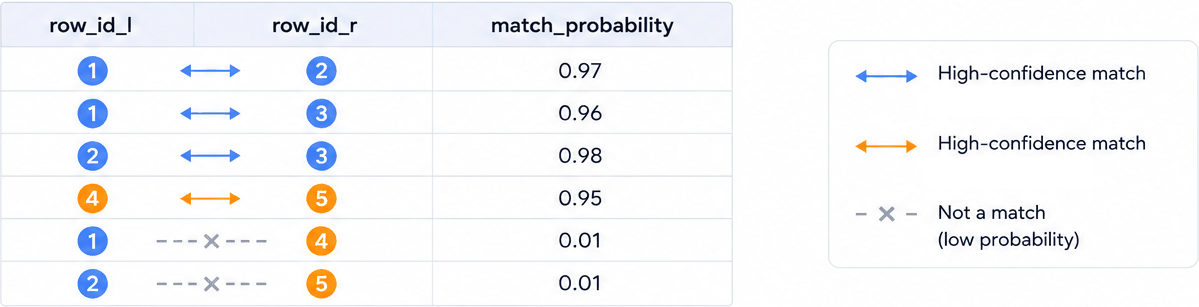
and clusters these links to produce an estimated person ID:
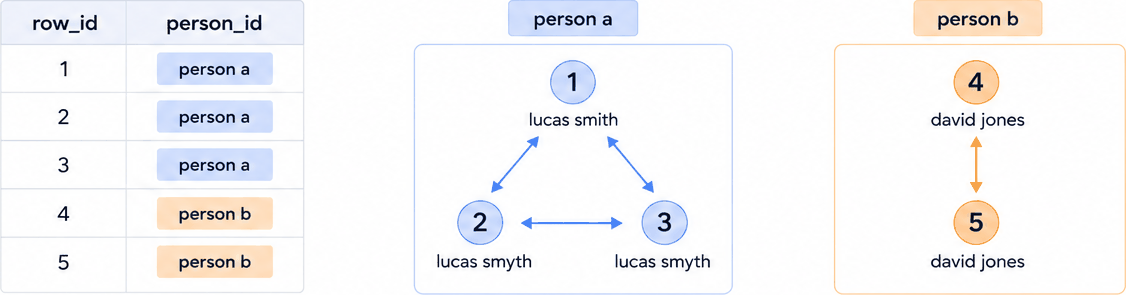
What data does Splink work best with?¶
Before using Splink, input data should be standardised, with consistent column names and formatting (e.g., lowercased, punctuation cleaned up, etc.).
Splink performs best with input data containing multiple columns that are not highly correlated. For instance, if the entity type is persons, you may have columns for full name, date of birth, and city. If the entity type is companies, you could have columns for name, turnover, sector, and telephone number.
High correlation occurs when the value of a column is highly constrained (predictable) from the value of another column. For example, a 'city' field is almost perfectly correlated with 'postcode'. Gender is highly correlated with 'first name'. Correlation is particularly problematic if all of your input columns are highly correlated.
Splink is not designed for linking a single column containing a 'bag of words'. For example, a table with a single 'company name' column, and no other details.
Videos¶
Our PyData Global 2024 talk provides a brief introduction to Splink and is available on YouTube here.
Support¶
If after reading the documentation you still have questions, please feel free to post on our discussion forum.
Use Cases¶
Here is a list of some of our known users and their use cases:
- Office for National Statistics's Business Index (formerly the Inter Departmental Business Register), Demographic Index and the 2021 Census. See also this article and 2021 Census to PDS linkage report.
- NHS England is working on developing an alternative data linkage model using splink as the core engine for a new probabilistic data linkage service. This is in order to improve linkage and linkage explainability across NHS datasets. Code now available on github.
- Ministry of Defence launched their Veteran's Card system which uses Splink to verify applicants against historic records. This project was shortlisted for the Civil Service Awards
- Ministry of Justice created linked datasets (combining courts, prisons and probation data) for use by researchers as part of the Data First programme
- Ministry of Justice and the BOLD programme used Splink to power the North Essex Probation Delivery Unit Case Information Dashboard, which won the 2025 Civil Service Award for Excellence in Delivery.
- UK Health Security Agency used Splink to link HIV testing data to national health records to evaluate the impact of emergency department opt-out bloodborne virus testing.
- The Department for Education uses Splink to match records from certain data providers to existing learners and reduce the volume of clerical work required for corrections
- SAIL Databank, in collaboration with Secure eResearch Platform (SeRP), uses Splink to produce linked cohorts for a wide range of population-level research applications
- Lewisham Council (London) identified and auto-enrolled over 500 additional eligible families to receive Free School Meals
- Leicestershire County Council use Splink to match individuals across their Education and Social Care systems. This ensures triage and front-line practitioners have a complete picture of those individuals.
- Integrated Corporate Services have used Splink to match address data in historical datasets, substantially improving match rates.
- London Office of Technology and Innovation created a dashboard to help better measure and reduce rough sleeping across London
- Competition and Markets Authority identified 'Persons with Significant Control' and estimated ownership groups across companies
- Office for Health Improvement and Disparities linked Health and Justice data to assess the pathways between probation and specialist alcohol and drug treatment services as part of the Better Outcomes through Linked Data programme
- Gateshead Council, in partnership with the National Innovation Centre for Data are creating a single view of debt
- Homes England has been working with the new developed Splink address matching version. We have succesfully tested and checked the linkage between Land Registry Price Paid dataset and the new Ordnance Survey National Geographical Dataset (NGD) but adddresses. The current linkage performs around 30 Million records in less than 5 hours with a high accuracy in a Databricks environment. This is helping Homes England with a vital component to identify and monitor new builds that will contribute to the 1.5 M homes mandate.
- The Department for Business and Trade plans to use Splink as part of Matchbox to reconcile business and product data for both analytical and operational use
- The Welsh Revenue Authority uses Splink in multiple linkage workflows to identify links in their own data, as well as to third party data for operational support in ensuring a fair tax system for Wales.
- Richmond Council and Wandsworth Council are using Splink to match residents’ records across systems to create unified records and a single view of debt.
- Westmorland & Furness Council used Splink to matched and de-duplicated Special Educational Needs and Disability (SEND) records across systems. This provided a “single view of the child”, improved data quality and automation, and laid the foundation for a wider “Single View of the Customer” initiative.
- 🇦🇺 The Australian Bureau of Statistics (ABS) used Splink to build the 2024 National Linkage Spine underpinning the National Disability Data Asset and will use Splink for the 2025 Person Linkage Spine build. They are also planning to use Splink for the Post Enumeration Survey as part of the 2026 Census quality assurance process.
- 🇩🇪 The German Federal Statistical Office (Destatis) uses Splink to conduct projects in linking register-based census data.
- 🇪🇺 The European Medicines Agency uses Splink to detect duplicate adverse event reports for veterinary medicines
- 🇺🇸 The Defense Health Agency (US Department of Defense) used Splink to identify duplicated hospital records across over 200 million data points in the military hospital data system
- 🌐 UNHCR uses Splink to analyse and enhance the quality of datasets by identifying and addressing potential duplicates.
- 🇨🇦 The Data Integration Unit at the Ontario Ministry of Children, Community, and Social Services are using Splink as their main data-integration tool for all intra- and inter-ministerial data-linking projects.
- 🇬🇲 Splink has been used to support the 2024 Gambian census by analysing and linking data from the census and the post-enumeration survey.
- 🇨🇦 Environment and Climate Change Canada is a user of Splink to connect datasets from various administrative and reporting programs.
- 🇨🇱🇬🇧 Chilean Ministry of Health and University College London have assessed the access to immunisation programs among the migrant population
- 🇺🇸 Florida Cancer Registry, published a feasibility study which showed Splink was faster and more accurate than alternatives
- 🇺🇸 Catalyst Cooperative's Public Utility Data Liberation Project links public financial and operational data from electric utilities for use by US climate advocates, policymakers, and researchers seeking to accelerate the transition away from fossil fuels.
- The University of Cambridge (CAMPOP) used Splink to perform the first full-count linking of English and Welsh censuses (1851–1921), integrating marriage and death registers to successfully track individuals across decades.
- Researchers from Harvard Medical School, Vanderbilt University Medical Center and Mass General Brigham used Splink for probabilistic linkage between 8.1 million internet media death records and EHR data, showing that online obituaries and memorial sites can improve mortality ascertainment by 18–24% over EHRs alone (American Journal of Epidemiology, 2025).
- Researchers from Princeton University, the University of Minnesota, and the Climate and Community Institute used Splink to link Enterprise-backed multifamily properties to eviction filings and rent listings, examining how federal mortgage financing relates to rent levels and eviction rates across the US rental market (Graetz et al., 2025).
- Stanford University investigated the impact of receiving government assistance has on political attitudes
- Bern University researched how Active Learning can be applied to Biomedical Record Linkage
- University of Pennsylvania, Princeton, and UC Berkeley researchers used Splink to link property data, voter files, and campaign donations, creating a dataset of 108M individuals to study the American voter base - see here.
- 🇱🇦 The Shared Child Health Record project in Lao PDR used Splink to de-duplicate pediatric records in a non-Latin script context
- Marie Curie have used Splink to build a single customer view on fundraising data which has been a "huge success [...] the tooling is just so much better. [...] The power of being able to select, plug in, configure and train a tool versus writing code. It's just mind boggling actually." Amongst other benefits, the system is expected to "dramatically reduce manual reporting efforts previously required". See also the blog post here.
- Club Brugge uses Splink to link football players from different data providers to their own database, simplifying and reducing the need for manual linkage labor.
- GN Group use Splink to deduplicate large volumes of customer records
- The Data City join Companies House open data to online job postings and published financial events keyed by company name and not company registration number to create a more complete picture of company activity in the UK.
Sadly, we don't hear about the majority of our users or what they are working on. If you have a use case and it is not shown here please add it to the list!
Awards¶
🥇 Civil Service Awards 2025: Innovation category - Winner
🥇 Civil Service Awards 2025: The Excellence In Delivery Award was won by a dashboard powered by Splink.
🥇 OpenUK Awards 2025: Open data category - Winner
🥈 Civil Service Awards 2023: Best Use of Data, Science, and Technology - Runner up
🥇 Analysis in Government Awards 2022: People's Choice Award - Winner
🥈 Analysis in Government Awards 2022: Innovative Methods - Runner up
🥇 Analysis in Government Awards 2020: Innovative Methods - Winner
🥇 Ministry of Justice Data and Analytical Services Directorate (DASD) Awards 2020: Innovation and Impact - Winner
Citation¶
If you use Splink in your research, we'd be grateful for a citation as follows:
@article{Linacre_Lindsay_Manassis_Slade_Hepworth_2022,
title = {Splink: Free software for probabilistic record linkage at scale.},
author = {Linacre, Robin and Lindsay, Sam and Manassis, Theodore and Slade, Zoe and Hepworth, Tom and Kennedy, Ross and Bond, Andrew},
year = 2022,
month = {Aug.},
journal = {International Journal of Population Data Science},
volume = 7,
number = 3,
doi = {10.23889/ijpds.v7i3.1794},
url = {https://ijpds.org/article/view/1794},
}
Acknowledgements¶
We are very grateful to ADR UK (Administrative Data Research UK) for providing the initial funding for this work as part of the Data First project.
We are extremely grateful to professors Katie Harron, James Doidge and Peter Christen for their expert advice and guidance in the development of Splink. We are also very grateful to colleagues at the UK's Office for National Statistics for their expert advice and peer review of this work. Any errors remain our own.