Splink Updates - December 2023¶
Welcome to the second installment of the Splink Blog!
Here are some of the highlights from the second half of 2023, and a taste of what is in store for 2024!
Latest Splink version: v3.9.10
 Charts Gallery¶
Charts Gallery¶
The Splink docs site now has a Charts Gallery to show off all of the charts that come out-of-the-box with Splink to make linking easier.
Each chart now has an explanation of:
- What the chart shows
- How to interpret it
- Actions to take as a result
This is the first step on a longer term journey to provide more guidance on how to evaluate Splink models and linkages, so watch this space for more in the coming months!
 New Charts¶
New Charts¶
We are always adding more charts to Splink - to understand how these charts are built see our new Charts Developer Guide.
Two of our latest additions are:
Confusion Matrix¶
When evaluating any classification model, a confusion matrix is a useful tool for summarising performance by representing counts of true positive, true negative, false positive, and false negative predictions.
Splink now has its own confusion matrix chart to show how model performance changes with a given match weight threshold.
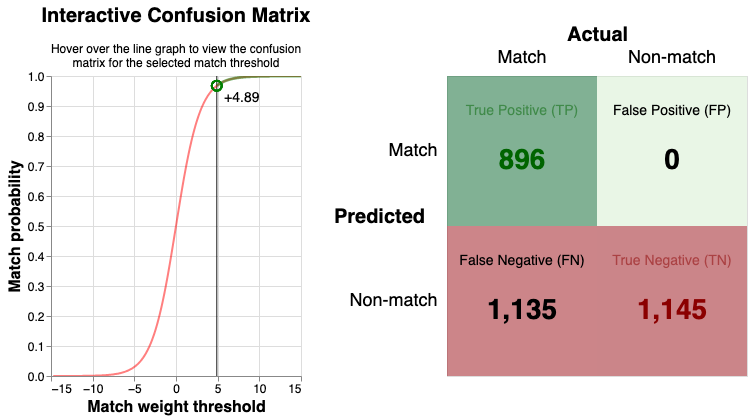
Note, labelled data is required to generate this chart.
Completeness Chart¶
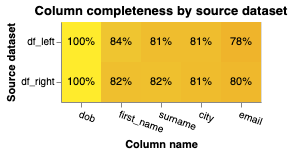
When linking multiple datasets together, one of the most important factors for a successful linkage is the number of common fields across the datasets.
Splink now has the completeness chart which gives a simple view of how well populated fields are across datasets.
 Settings Validation¶
Settings Validation¶
The Settings dictionary is central to everything in Splink. It defines everything from the SQL dialect of your backend to how features are compared in Splink model.
A common sticking point with users is how easy it is to make small errors when defining the Settings dictionary, resulting in unhelpful error messages.
To address this issue, the Settings Validator provides clear, user-friendly feedback on what the issue is and how to fix it.
Blocking Rule Library (Improved)¶
In our previous blog we introduced the Blocking Rule Library (BRL) built upon the exact_match_rule function. When testing this functionality we found it pretty verbose, particularly when blocking on multiple columns, so figured we could do better. From Splink v3.9.6 we introduced the block_on function to supersede exact_match_rule.
For example, a block on first_name and surname now looks like:
from splink.duckdb.blocking_rule_library import block_on
block_on(["first_name", "surname"])
as opposed to
import splink.duckdb.blocking_rule_library as brl
brl.and_(
brl.exact_match_rule("first_name"),
brl.exact_match_rule("surname")
)
All of the tutorials, example notebooks and docs have been updated to use block_on.
 Backend Specific Installs¶
Backend Specific Installs¶
Some users have had difficulties downloading Splink due to additional dependencies, some of which may not be relevant for the backend they are using. To solve this, you can now install a minimal version of Splink for your given SQL engine.
For example, to install Splink purely for Spark use the command:
pip install 'splink[spark]'
See the Getting Started page for further guidance.
 Drop support for python 3.7¶
Drop support for python 3.7¶
From Splink 3.9.7, support has been dropped for python 3.7. This decision has been made to manage dependency clashes in the back end of Splink.
If you are working with python 3.7, please revert to Splink 3.9.6.
pip install splink==3.9.6
 What's in the pipeline?¶
What's in the pipeline?¶
 Work on Splink 4 is currently underway
Work on Splink 4 is currently underway- More guidance on how to evaluate Splink models and linkages