Blocking Rules for Splink Predictions¶
Prediction Blocking Rules choose which record pairs from a dataset get considered and scored by the Splink model.
The aim of Prediction Blocking Rules are to:
- Capture as many true matches as possible
- Reduce the total number of comparisons being generated
Using Prediction Rules in Splink¶
Blocking Rules for Prediction are defined through blocking_rules_to_generate_predictions in the Settings dictionary of a model. For example:
settings = {
"link_type": "dedupe_only",
"blocking_rules_to_generate_predictions": [
brl.block_on(["first_name", "surname"]),
brl.block_on("dob"),
],
"comparisons": [
ctl.name_comparison("first_name"),
ctl.name_comparison("surname"),
ctl.date_comparison("dob", cast_strings_to_date=True),
cl.exact_match("city", term_frequency_adjustments=True),
ctl.email_comparison("email"),
],
}
will generate comparisons for all true matches where names match. But it would miss a true match where there was a typo in (say) the first name.
In general, it is usually impossible to find a single rule which both:
-
Reduces the number of comparisons generated to a computationally tractable number
-
Ensures comparisons are generated for all true matches
This is why blocking_rules_to_generate_predictions is a list. Suppose we also block on postcode:
settings_example = {
"blocking_rules_to_generate_predictions" [
brl.block_on(["first_name", "surname"]),
brl.block_on("postcode")
]
}
This generates all pairwise comparisons that satisfy at least one of the rules.
We will now generate a pairwise comparison for the record where there was a typo in the first name, so long as there isn't also a difference in the postcode.
By specifying a variety of blocking_rules_to_generate_predictions, it becomes unlikely that a truly matching record would not be captured by at least one of the rules.
Note
Unlike Training Rules, Prediction Rules are considered collectively, and are order-dependent. So, in the example above, the l.postcode = r.postcode blocking rule only generates record comparisons that are a match on postcode were not already captured by the first_name and surname rule.
Choosing Prediction Rules¶
When defining blocking rules it is important to consider the number of pairwise comparisons being generated your the blocking rules. There are a number of useful functions in Splink which can help with this.
Once a linker has been instated, we can use the cumulative_num_comparisons_from_blocking_rules_chart function to look at the cumulative number of comparisons generated by blocking_rules_to_generate_predictions. For example, a setting dictionary like this:
settings = {
"blocking_rules_to_generate_predictions": [
brl.block_on("first_name"),
brl.block_on("surname")
],
}
will generate the something like:
linker = DuckDBLinker(df, settings)
linker.cumulative_num_comparisons_from_blocking_rules_chart()
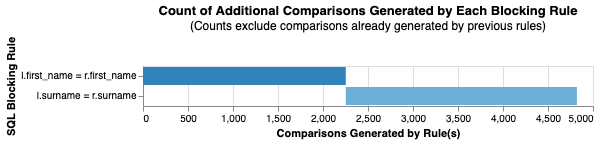
Where, similar to the note above, the l.surname = r.surname bar in light blue is a count of all record comparisons that match on surname that have not already been captured by the first_name rule.
You can also return the underlying data for this chart using the cumulative_comparisons_from_blocking_rules_records function:
linker.cumulative_comparisons_from_blocking_rules_records()
[{'row_count': 2253, 'rule': 'l.first_name = r.first_name'}, {'row_count': 2568, 'rule': 'l.surname = r.surname'}]