completeness_chart¶
At a glance
Useful for: Looking at which columns are populated across datasets.
API Documentation: completeness_chart()
What is needed to generate the chart? A linker with some data.
Worked Example¶
from splink.duckdb.linker import DuckDBLinker
import splink.duckdb.comparison_library as cl
import splink.duckdb.comparison_template_library as ctl
from splink.duckdb.blocking_rule_library import block_on
from splink.datasets import splink_datasets
import logging, sys
logging.disable(sys.maxsize)
# Split a simple dataset into two, separate datasets which can be linked together.
df_l = df.sample(frac=0.5)
df_r = df.drop(df_l.index)
settings = {
"link_type": "link_only",
"blocking_rules_to_generate_predictions": [
block_on("first_name"),
block_on("surname"),
],
"comparisons": [
ctl.name_comparison("first_name"),
ctl.name_comparison("surname"),
ctl.date_comparison("dob", cast_strings_to_date=True),
cl.exact_match("city", term_frequency_adjustments=True),
ctl.email_comparison("email", include_username_fuzzy_level=False),
],
}
linker = DuckDBLinker([df_l, df_r], settings, input_table_aliases=["df_left", "df_right"])
linker.completeness_chart(cols=["first_name", "surname", "dob", "city", "email"])
What the chart shows¶
The completeness_chart shows the proportion of populated (non-null) values in the columns of multiple datasets.
What the chart tooltip shows
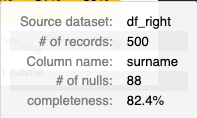
The tooltip shows a number of values based on the panel that the user is hovering over, including:
- The dataset and column name
- The count and percentage of non-null values in the column for the relelvant dataset.
How to interpret the chart¶
Each panel represents the percentage of non-null values in a given dataset-column combination. The darker the panel, the lower the percentage of non-null values.
Actions to take as a result of the chart¶
Only choose features that are sufficiently populated across all datasets in a linkage model.