Part 3 Analytical Data Store (ADS) Architecture
3.1 Architecture Principles
Principle - 1: Simple and flexible Architecture
Statement: The ADS architecture should be constructed so as to make the introduction of new capabilities or functionalities as simple as possible
Rationale: The ADS architecture should not complicate the onboarding of new data sources, rather it should support reusable common code base for different data sources and components that onboarding new data sources is quick and time efficient
Implementation: Wherever possible common ETL code is used across components and data sources
Principle - 2: Traceability and Audit-ability
Statement: Changes to data mappings between components will be tracked and available
Rationale: The ADS should support the enablement of auditability, traceability and reversibility i.e. full lineage from the point of consumption, across the analytical environment to its source system, with the ability to reverse out and correct any errors in any of the layers.
Implementation: This will be supported by appropriate technical metadata, error handling framework and mapping documentation
Principle - 3: Optimised for performance
Statement: The data should be transformed and optimised in ADS for better performance
Rationale: The Data Engineers, Analysts and Scientists should spend less time in transforming and optimising data and more time on driving value from Data
Implementation: Wherever possible, transformations will be applied on the data in curated layer i.e. data will not be moved outside of the storage area just for transformation purposes.
Principle - 4: Data is a shared asset
Statement: Data is an Asset and should be treated as such. It presents MOJ with both potential value and risk. Also, make data accessible to all authorised users
Rationale: Data is a valuable resource for the ministry. It has real, measurable value. It is critical for accurate and timely decisions. Shared data will result in increased efficiency instead of departmental silos to persist, this will ensure all the stake holders have common and complete view (i.e. 360-degree) of the MOJ data
Implementation: One of the key drivers behind this programme is to treat data as an asset. The majority of the design is around how this data is handled. The is also a separate section, specifically on data modelling
Principle - 5: Data is secured
Statement: Data is protected from any unauthorised use and disclosure.
Rationale: Given the sensitivity of the data in the ministry, data security is one of the top priorities for MOJ. Highly open sharing of information and the release of information via relevant legislation must be balanced against the need to restrict the availability of classified, proprietary, and sensitive information.
Implementation: Data security is implemented with strict IAM roles and other security framework in place. Also, frequent auditing and monitoring of data usage is in place to ensure any abnormal activities are captured and actioned appropriately
Principle - 6: Data is of high quality
Statement: Data quality will need to be measured and steps taken to improve data quality
Rationale: To make sure those accessing the data can trust it, making it a reliable source on which to make decisions.
Implementation: Data Quality and data integrity rules are embed in the code to makes sure the data is of good quality and ADS platform take ownership to notify and work with data source teams/data stewards to constantly improve the quality
3.2 Conceptual Architecture Diagram
This section describes storage, processing and consumption layers through the ADS eco system enabling a multi-tenant platform to be built in line with delivering expected platform capabilities.

component Description | NAME | DESCRIPTION | | :— | :— | | Landing |Landing area for files to be processed| | Landing - Data Masking |Landing area for files where data needs to be masked before processed further| | Raw | A transient repository for files passed validation| | Raw History | Repository of all data files received, files stored here have no processing applied| | Stage | First governed layer where data is landed with data governance practices applied, data enriched by reformatting to standard data types, partitioned in S3 bucket for better storage with appropriate compression| | Curated | Holds data that is transformed, business rules applied, integrated with data from other source systems, aggregated tables/custom views are built for consumption by other tools| |Consumption | Data is access by various data analysis tools for data discovery, trend analysis, Descriptive analytics etc|
3.3 Logical Dataflow Diagram
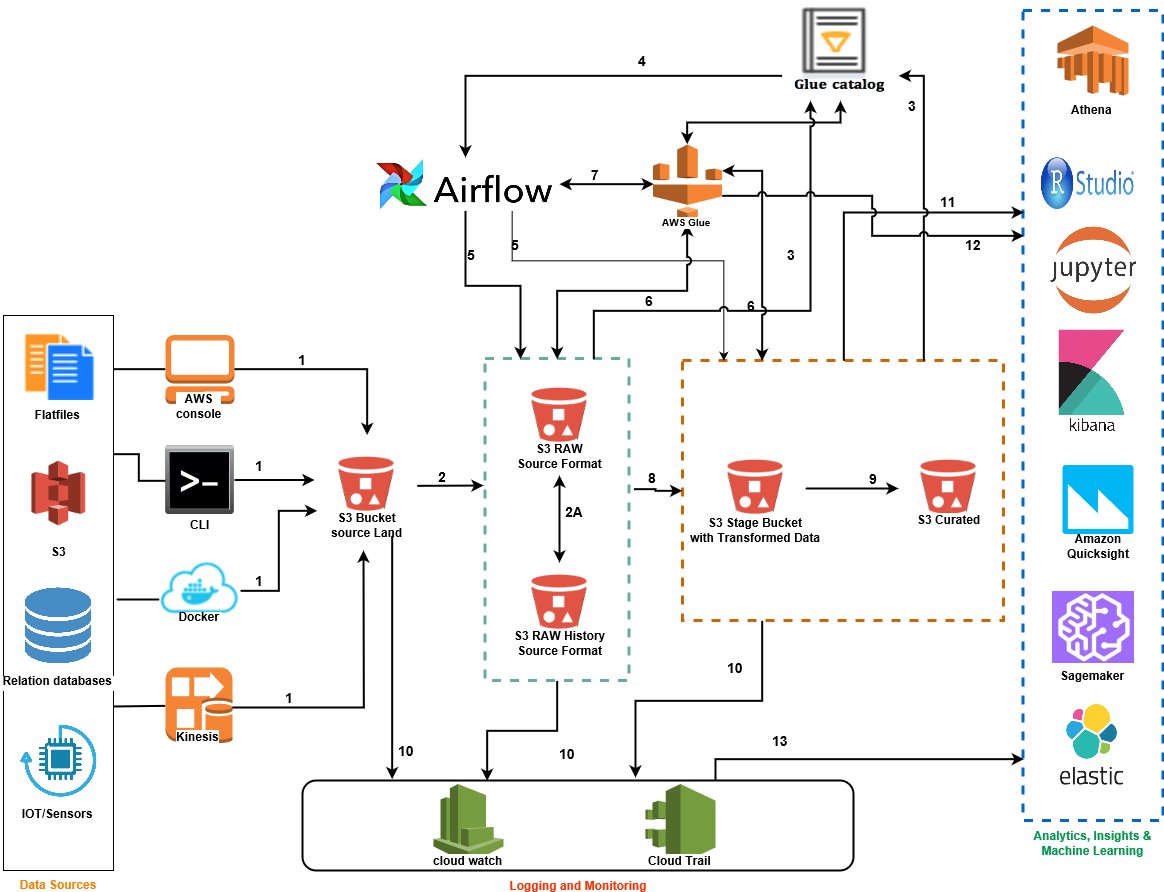
3.3.1 Data Flows
Data flow Description
| Flow ID | Name | Description |
|---|---|---|
| 1 | Source to Land | Files are placed in appropriate s3 landing bucket by source providers |
| 2 | Land to Raw | Event based Airflow scheduler to read files from S3 landing and move to S3 Raw bucket in the Raw data format |
| 2A | Raw to Raw History | Files that pass validation are passed to s3 Raw history with no transrformation info |
| 3 | Glue Catalog | Meta data cataloged in Glue, data crawlers might be used for automated data catalogging |
| 4 | Glue Catalog to Airflow | Files that pass validation are passed to s3 Raw history with no transrformation info |
| 5 | Raw to Raw History | Files that pass validation are passed to s3 Raw history with no transrformation info |
| 6 | Raw to Raw History | Files that pass validation are passed to s3 Raw history with no transrformation info |
3.3.2 Things to consider for onboarding new
3.4 Data Architecture
3.4.1 Data Modelling Principles
Architecture Principles applied to Data Modelling (also known as Key Principles) This section describes key architecture principles and their applicability to data modelling.
3.4.1.1 Principle 1 - Simplicity
Statement: Design should be as simple as possible. The data model diagrams should be laid out in a way that makes the data model easy to read (i.e. limited number of entities, verb phase to describe every relation). #### Principle 2 - Extensibility Statement: Designs should be extensible in areas where it is reasonable to expect requirements to change in the short to medium term
3.4.1.2 Principle 3 - Isolation
Statement: Designs should provide for the implementation of independent components that can be reused and recombined.
3.4.1.3 Principle 4 - Scalability
Statement: Designs should allow for anticipated future growth in a way that minimises costs and ensures performance.
3.4.1.4 Principle 5 - Integrity
Statement: Designs must assure the accuracy and consistency of the data from source to target.
Audit and traceability columns are added during the process instantiating the logical model to its physical implementation. The different models produced must inter-operate and be consistent between each other. The different models are linked together by the mapping specifications describing transformation and derivation logic.